Publications
Papers
2025
-
 The Station: An Open-World Environment for AI-Driven DiscoveryStephen Chung, and Wenyu DuarXiv preprint arXiv:2511.06309, 2025
The Station: An Open-World Environment for AI-Driven DiscoveryStephen Chung, and Wenyu DuarXiv preprint arXiv:2511.06309, 2025We introduce the STATION, an open-world multi-agent environment that models a miniature scientific ecosystem. Leveraging their extended context windows, agents in the Station can engage in long scientific journeys that include reading papers from peers, formulating hypotheses, submitting code, performing analyses, and publishing results. Importantly, there is no centralized system coordinating their activities - agents are free to choose their own actions and develop their own narratives within the Station. Experiments demonstrate that AI agents in the Station achieve new state-of-the-art performance on a wide range of benchmarks, spanning from mathematics to computational biology to machine learning, notably surpassing AlphaEvolve in circle packing. A rich tapestry of narratives emerges as agents pursue independent research, interact with peers, and build upon a cumulative history. From these emergent narratives, novel methods arise organically, such as a new density-adaptive algorithm for scRNA-seq batch integration. The Station marks a first step towards autonomous scientific discovery driven by emergent behavior in an open-world environment, representing a new paradigm that moves beyond rigid optimization.
-
 Interpreting Emergent Planning in Model-Free Reinforcement LearningThomas Bush, Stephen Chung, Usman Anwar, and 2 more authorsIn The Thirteenth International Conference on Learning Representations (Oral), 2025
Interpreting Emergent Planning in Model-Free Reinforcement LearningThomas Bush, Stephen Chung, Usman Anwar, and 2 more authorsIn The Thirteenth International Conference on Learning Representations (Oral), 2025We present the first mechanistic evidence that model-free reinforcement learning agents can learn to plan. This is achieved by applying a methodology based on concept-based interpretability to a model-free agent in Sokoban – a commonly used benchmark for studying planning. Specifically, we demonstrate that DRC, a generic model-free agent introduced by Guez et al. (2019), uses learned concept representations to internally formulate plans that both predict the long-term effects of actions on the environment and influence action selection. Our methodology involves: (1) probing for planning-relevant concepts, (2) investigating plan formation within the agent’s representations, and (3) verifying that discovered plans (in the agent’s representations) have a causal effect on the agent’s behavior through interventions. We also show that the emergence of these plans coincides with the emergence of a planning-like property: the ability to benefit from additional test-time compute. Finally, we perform a qualitative analysis of the planning algorithm learned by the agent and discover a strong resemblance to parallelized bidirectional search. Our findings advance understanding of the internal mechanisms underlying planning behavior in agents, which is important given the recent trend of emergent planning and reasoning capabilities in LLMs through RL.
-
 Thinker: Learning to Think Fast and SlowStephen Chung, Wenyu Du, and Jie FuIn Advances in Neural Information Processing Systems, 2025
Thinker: Learning to Think Fast and SlowStephen Chung, Wenyu Du, and Jie FuIn Advances in Neural Information Processing Systems, 2025Recent studies show that the reasoning capabilities of Large Language Models (LLMs) can be improved by applying Reinforcement Learning (RL) to question-answering (QA) tasks in areas such as math and coding. With a long context length, LLMs may learn to perform search, as indicated by the self-correction behavior observed in DeepSeek R1. However, this search behavior is often imprecise and lacks confidence, resulting in long, redundant responses and highlighting deficiencies in intuition and verification. Inspired by the Dual Process Theory in psychology, we introduce a simple modification to the QA task that includes four stages: Fast Thinking, where the LLM must answer within a strict token budget; Verification, where the model evaluates its initial response; Slow Thinking, where it refines the initial response with more deliberation; and Summarization, where it distills the refinement from the previous stage into precise steps. Our proposed task improves average accuracy from 25.6% to 27.3% for Qwen2.5-1.5B, and from 45.9% to 51.0% for DeepSeek-R1-Qwen-1.5B. Notably, for Qwen2.5-1.5B, the Fast Thinking mode alone achieves 25.2% accuracy using fewer than 1000 tokens, demonstrating substantial inference efficiency gains. These findings suggest that intuition and deliberative reasoning are distinct, complementary systems benefiting from targeted training. Additionally, we have open-sourced both the trained models and the source code.
{kind=link}
2024
-
 Predicting Future Actions of Reinforcement Learning AgentsStephen Chung, Scott Niekum, and David KruegerIn Advances in Neural Information Processing Systems, 2024
Predicting Future Actions of Reinforcement Learning AgentsStephen Chung, Scott Niekum, and David KruegerIn Advances in Neural Information Processing Systems, 2024As reinforcement learning agents become increasingly deployed in real-world scenarios, predicting future agent actions and events during deployment is important for facilitating better human-agent interaction and preventing catastrophic outcomes. This paper experimentally evaluates and compares the effectiveness of future action and event prediction for three types of RL agents: explicitly planning, implicitly planning, and non-planning. We employ two approaches: the inner state approach, which involves predicting based on the inner computations of the agents (e.g., plans or neuron activations), and a simulation-based approach, which involves unrolling the agent in a learned world model. Our results show that the plans of explicitly planning agents are significantly more informative for prediction than the neuron activations of the other types. Furthermore, using internal plans proves more robust to model quality compared to simulation-based approaches when predicting actions, while the results for event prediction are more mixed. These findings highlight the benefits of leveraging inner states and simulations to predict future agent actions and events, thereby improving interaction and safety in real-world deployments.
2023
-
 Thinker: Learning to Plan and ActStephen Chung, Ivan Anokhin, and David KruegerIn Advances in Neural Information Processing Systems, 2023
Thinker: Learning to Plan and ActStephen Chung, Ivan Anokhin, and David KruegerIn Advances in Neural Information Processing Systems, 2023We propose the Thinker algorithm, a novel approach that enables reinforcement learning agents to autonomously interact with and utilize a learned world model. The Thinker algorithm wraps the environment with a world model and introduces new actions designed for interacting with the world model. These model-interaction actions enable agents to perform planning by proposing alternative plans to the world model before selecting a final action to execute in the environment. This approach eliminates the need for handcrafted planning algorithms by enabling the agent to learn how to plan autonomously and allows for easy interpretation of the agent’s plan with visualization. We demonstrate the algorithm’s effectiveness through experimental results in the game of Sokoban and the Atari 2600 benchmark, where the Thinker algorithm achieves state-of-the-art performance and competitive results, respectively. Visualizations of agents trained with the Thinker algorithm demonstrate that they have learned to plan effectively with the world model to select better actions. Thinker is the first work showing that an RL agent can learn to plan with a learned world model in complex environments.
2022
-
 Learning by competition of self-interested reinforcement learning agentsStephen ChungIn Proceedings of the AAAI Conference on Artificial Intelligence, 2022
Learning by competition of self-interested reinforcement learning agentsStephen ChungIn Proceedings of the AAAI Conference on Artificial Intelligence, 2022An artificial neural network can be trained by uniformly broadcasting a reward signal to units that implement a REINFORCE learning rule. Though this presents a biologically plausible alternative to backpropagation in training a network, the high variance associated with it renders it impractical to train deep networks. The high variance arises from the inefficient structural credit assignment since a single reward signal is used to evaluate the collective action of all units. To facilitate structural credit assignment, we propose replacing the reward signal to hidden units with the change in the L2 norm of the unit’s outgoing weight. As such, each hidden unit in the network is trying to maximize the norm of its outgoing weight instead of the global reward, and thus we call this learning method Weight Maximization. We prove that Weight Maximization is approximately following the gradient of rewards in expectation. In contrast to backpropagation, Weight Maximization can be used to train both continuous-valued and discrete-valued units. Moreover, Weight Maximization solves several major issues of backpropagation relating to biological plausibility. Our experiments show that a network trained with Weight Maximization can learn significantly faster than REINFORCE and slightly slower than backpropagation. Weight Maximization illustrates an example of cooperative behavior automatically arising from a population of self-interested agents in a competitive game without any central coordination.
- Faster Learning with a Team of Reinforcement Learning AgentsStephen Chung, and Andrew BartoReinforcement Learning and Decision Making, 2022
Though backpropagation underlies nearly all deep learning algorithms, it is generally regarded as being biologically implausible. An alternative way of training an artificial neural network is through making each unit stochastic and treating each unit as a reinforcement learning agent, and thus the network is considered as a team of agents. As such, all units can learn via REINFORCE, a local learning rule modulated by a global reward signal that is more consistent with biologically observed forms of synaptic plasticity. However, this learning method suffers from high variance and thus the low speed of learning. The high variance stems from the lack of effective structural credit assignment. This paper reviews two recently proposed algorithms to facilitate structural credit assignment when all units learn via REINFORCE, namely MAP Propagation and Weight Maximization. In MAP Propagation an energy function of the network is minimized before applying REINFORCE, such that activities of hidden units are more consistent with the activities of output units. In Weight Maximization the global reward signal to each hidden unit is replaced with the change in the squared L2 norm of the vector of the unit’s outgoing weights, such that each hidden unit is trying to maximize the norm of its outgoing weights instead of the external reward. Experiments show that both algorithms can learn significantly faster than a network of units learning via REINFORCE, and have a comparable speed to backpropagation when applied in standard reinforcement learning tasks. In contrast to backpropagation, both algorithms retain certain biologically plausible properties of REINFORCE, such as having local learning rules and the ability to be computed asynchronously. Therefore these algorithms may offer insights for understanding possible mechanisms of structural credit assignment in biological neural systems.
2021
-
 MAP Propagation Algorithm: Faster Learning with a Team of Reinforcement Learning AgentsStephen ChungIn Advances in Neural Information Processing Systems, 2021
MAP Propagation Algorithm: Faster Learning with a Team of Reinforcement Learning AgentsStephen ChungIn Advances in Neural Information Processing Systems, 2021Nearly all state-of-the-art deep learning algorithms rely on error backpropagation, which is generally regarded as biologically implausible. An alternative way of training an artificial neural network is through treating each unit in the network as a reinforcement learning agent, and thus the network is considered as a team of agents. As such, all units can be trained by REINFORCE, a local learning rule modulated by a global signal that is more consistent with biologically observed forms of synaptic plasticity. Although this learning rule follows the gradient of return in expectation, it suffers from high variance and thus the low speed of learning, rendering it impractical to train deep networks. We therefore propose a novel algorithm called MAP propagation to reduce this variance significantly while retaining the local property of the learning rule. Experiments demonstrated that MAP propagation could solve common reinforcement learning tasks at a similar speed to backpropagation when applied to an actor-critic network. Our work thus allows for the broader application of teams of agents in deep reinforcement learning.
-
 Turing Completeness of Bounded-Precision Recurrent Neural NetworksStephen Chung, and Hava SiegelmannIn Advances in Neural Information Processing Systems, 2021
Turing Completeness of Bounded-Precision Recurrent Neural NetworksStephen Chung, and Hava SiegelmannIn Advances in Neural Information Processing Systems, 2021Previous works have proved that recurrent neural networks (RNNs) are Turing-complete. However, in the proofs, the RNNs allow for neurons with unbounded precision, which is neither practical in implementation nor biologically plausible. To remove this assumption, we propose a dynamically growing memory module made of neurons of fixed precision. The memory module dynamically recruits new neurons when more memories are needed, and releases them when memories become irrelevant. We prove that a 54-neuron bounded-precision RNN with growing memory modules can simulate a Universal Turing Machine, with time complexity linear in the simulated machine’s time and independent of the memory size. The result is extendable to various other stack-augmented RNNs. Furthermore, we analyze the Turing completeness of both unbounded-precision and bounded-precision RNNs, revisiting and extending the theoretical foundations of RNNs.
2020
-
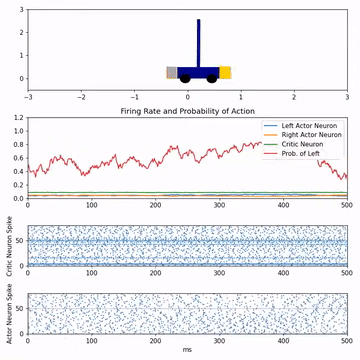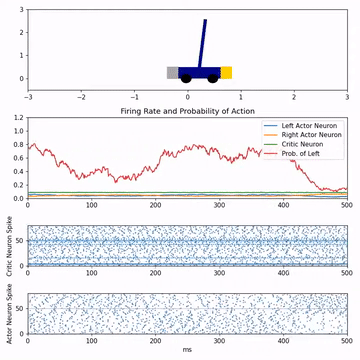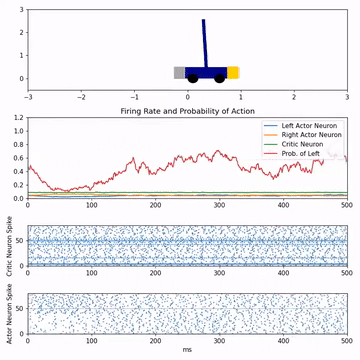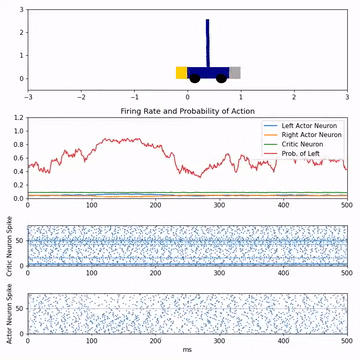 Reinforcement learning with feedback-modulated TD-STDPStephen Chung, and Robert KozmaarXiv preprint arXiv:2008.13044, 2020
Reinforcement learning with feedback-modulated TD-STDPStephen Chung, and Robert KozmaarXiv preprint arXiv:2008.13044, 2020Spiking neuron networks have been used successfully to solve simple reinforcement learning tasks with continuous action set applying learning rules based on spike-timing-dependent plasticity (STDP). However, most of these models cannot be applied to reinforcement learning tasks with discrete action set since they assume that the selected action is a deterministic function of firing rate of neurons, which is continuous. In this paper, we propose a new STDP-based learning rule for spiking neuron networks which contains feedback modulation. We show that the STDP-based learning rule can be used to solve reinforcement learning tasks with discrete action set at a speed similar to standard reinforcement learning algorithms when applied to the CartPole and LunarLander tasks. Moreover, we demonstrate that the agent is unable to solve these tasks if feedback modulation is omitted from the learning rule. We conclude that feedback modulation allows better credit assignment when only the units contributing to the executed action and TD error participate in learning.
Research Reports
2022
-
- Structural Credit Assignment with Coordinated ExplorationStephen ChungarXiv preprint arXiv:2307.13256, 2022